The Azure Bakery series: Resource groups
Resource groups allow you to group resources that share the same life cycle. We’ll look at resource groups, regions, a naming convention, and tagging strategy.


Welcome back for the fourth layer of our cake. The third layer was subscriptions. Today, we’ll look at resource groups, regions, a naming convention, and tagging strategy.
Azure consists of numerous regions; going through them helps solidify your understanding. Having a naming convention and tagging strategy in place allows you to quickly identify resources and their details, which is crucial for the governance of your Azure environment.
Resource groups
Resource groups are containers for resources; they allow you to group them. Resources in a resource group share the same lifecycle and can only exist in one resource group simultaneously. You can move, add or remove resources at any time.
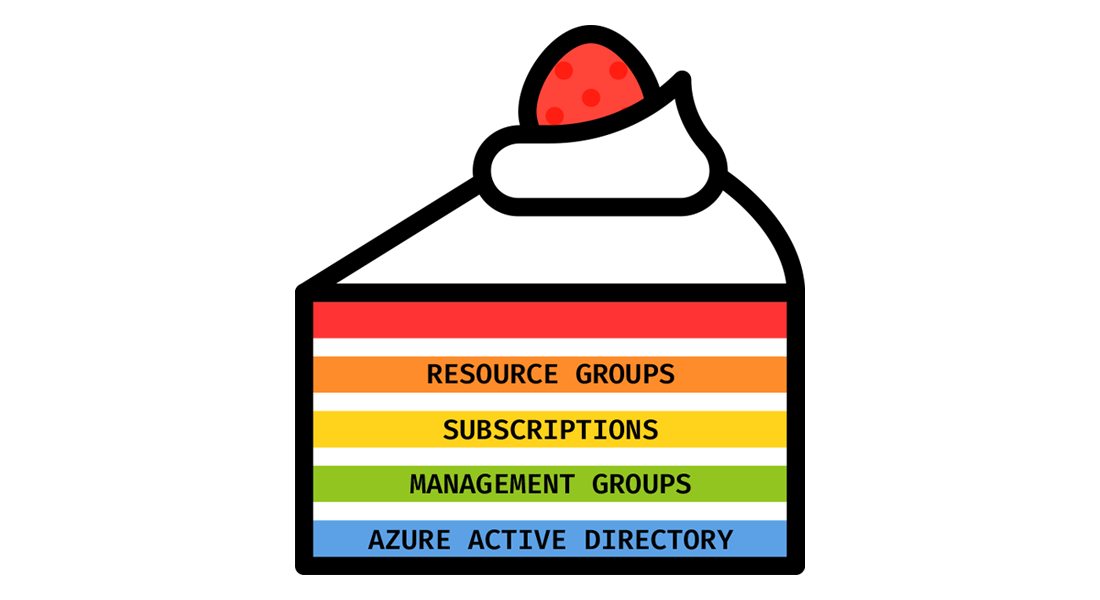
When you create a resource group, you must provide a location, the region. We’ll go through the details of the regions later in this post. The resource group contains metadata about its resources. By specifying the resource group’s location, you’re selecting where the metadata is stored, which can be essential for compliance reasons.
If you delete a resource group, you’ll delete the resources located in that resource group. Just as with subscriptions and most other services, there are limits. You can deploy up to 800 resources in a single resource group.
Resource groups and resources can have a lock, so-called delete, and read-only locks, allowing you to lock down workloads for deletion or modification.
A delete lock means you can still modify the resource group and its resources but not delete them. In comparison, the read-only lock means you can’t alter or delete the resource group and its resources.
Regions
Azure is a global cloud service platform and comprises two key components—the physical infrastructure and the network. The physical infrastructure includes 160+ data centers divided across 54 regions, connected through the global Azure network.
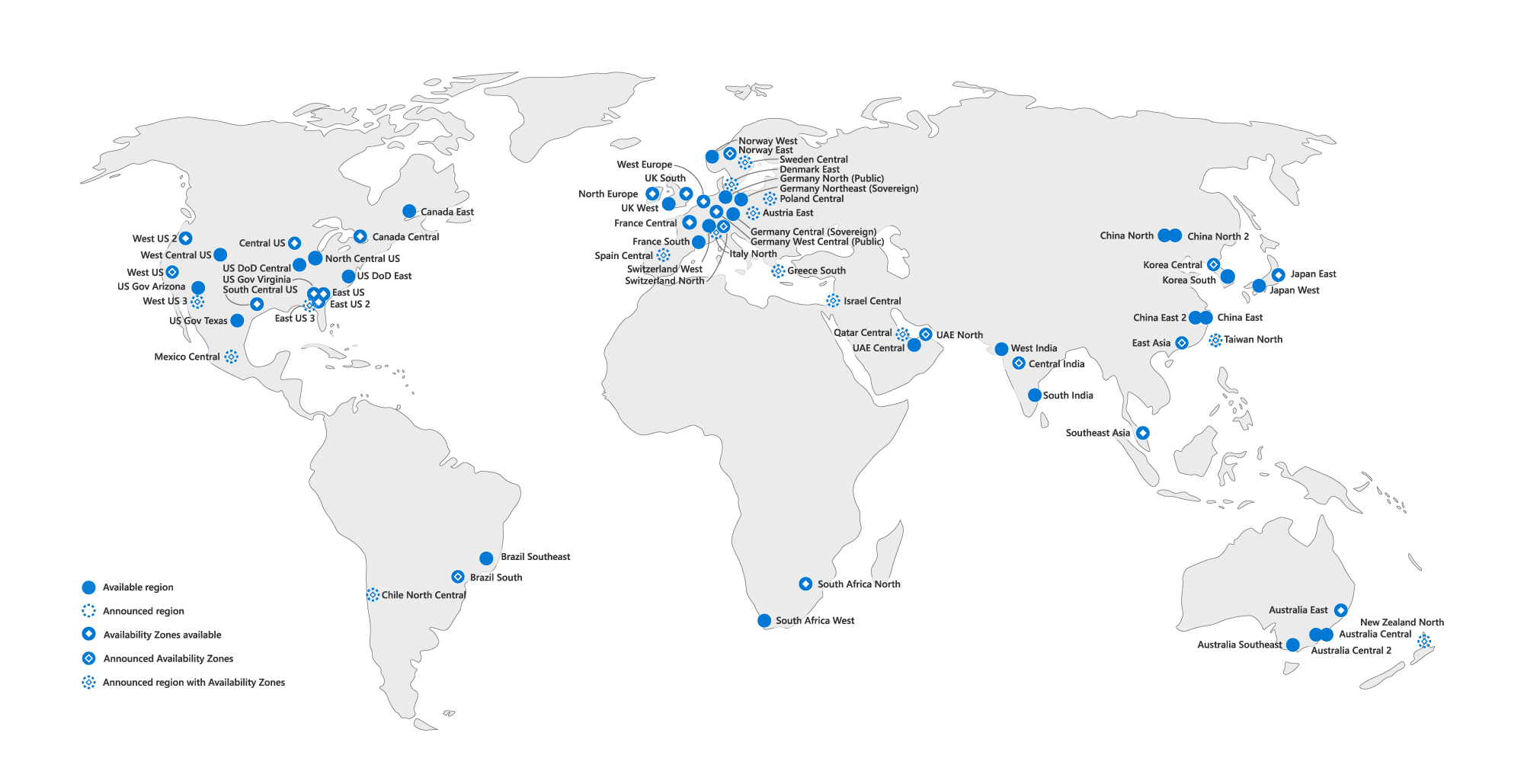
A region is a set of data centers to ensure high availability. Each region has a pair. This pair is another region, preferably located at least 300 miles (482 kilometers) apart, which is sometimes impossible. Most of the pairs are directly connected. Utilizing a regional pair when replicating data or building and deploying multi-regional workloads is recommended. For example, the regional pair for West Europe is North Europe. Click here for the regional pairs. You can find more information about the cross-region replication pairings for all geographies in the documentation.
When Microsoft updates the Azure infrastructure, only one of the pairs will be updated simultaneously to prevent a complete geographic outage if something goes wrong. When an unplanned outage affects multiple regions, at least one of the regional pairs is prioritized to recover service.
Naming convention
A good and solid naming convention is essential to identify resources. Adding the most critical information makes it possible to quickly determine the resource’s type, workload, and deployment environment. There’s no one-size-fits-all approach; the naming convention can differ per organization.
It’s not possible to rename resources after you’ve deployed them. Therefore, it’s essential to establish a naming convention before deploying resources and migrating production workloads.
All resource types have a naming scope that defines the scope in which the name should be unique; the naming scopes are:
- The resource attributes scope, where the name must be unique within the resource—for example, a subnet within a virtual network.
- The resource group scope, where the name has to be unique within the resource group.
- The global scope, where the name has to be unique throughout Azure.
Microsoft advises a naming convention that starts with the resource type and ends with an instance number. There are recommended naming components, abbreviations per resource type, and limits to consider. I’ll take you through these recommendations from left to right and give my take on this.
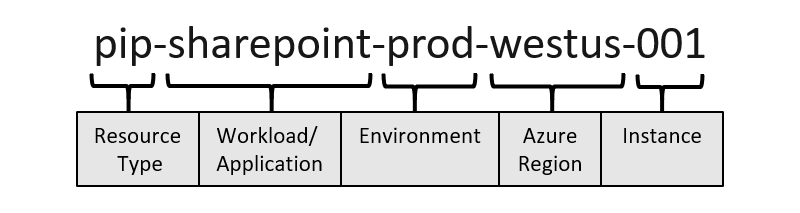
Resource type: This abbreviation represents the resource type and is used as a prefix (beginning) or suffix (ending). There’s a recommended abbreviations overview available in the documentation.
Workload or application: The name or identifier of the application or workload that the resource belongs to. Try to keep this as short as possible. A great option is to use a four or five-digit identifier representing the application—for example, 0281 instead of sharepoint. When using numbers, keeping track of them and their application is essential. Tags can help by adding the full application name as a tag.
Deployment environment: This represents the stage of the development lifecycle. Try to keep this as short as possible by using letters like p instead of prod or d instead of dev.
Region: The geographical Azure region where the resource is deployed. Use this only when you’re utilizing multiple regions. And even then, maybe only for network resources. Try to keep this as short as possible by using abbreviations—for example, weu instead of westeurope, or wus instead of westus.
Instance: A two or three-digit number is used to differentiate multiple instances of the same resource. Determine for which resource types this is appropriate. Is there a chance I have numerous instances of the same resource?
There are naming limitations in place, and these limits can differ per resource type. For example, the name of a virtual machine (Windows) can not have more than 15 characters. In comparison, a storage account can have up to 24 characters but can only include lowercase letters and numbers. You can find more information about the naming rules and restrictions in the documentation.
Tagging strategy
Having a tagging policy in place is crucial for the governance of your Azure environment. Tags allow you to include more details (metadata) of your workloads on top of the naming convention’s information. You can filter and create reports based on this information.
Tags consist of key-value pairs and can, for example, include information about the resource’s workload name, data classification, business criticality and unit, cost center, owner, or who’s responsible for the workload. As the naming convention, there’s no one-size-fits-all approach; the tagging strategy can differ per organization.
Your tags can, for example, look like this:
- WorkloadName: Web Application
- DataClassification: Public
- Criticality: Medium
- BusinessUnit: Marketing
- CostCenter: 7629
- Owner: john.doe@robino.io
There are limits for tags in place as well. Each subscription, resource group, and resource can have up to 50 tags. Generally, the tag name (key) can have 512 characters, whereas the information (value) is limited to 256 characters. Not all the resource types support tagging; you can find the support information in the documentation.
Up next
Thank you so much for taking the time to read this post. I’d love to hear what you think, and I hope to see you next week when we’re going through the last layer of our cake, resources.
With the final layer, we’ll add resources to the ingredients of all previous layers. With these resources, the layers of the cake come together, making it ready to serve! Bye for now!



